监督学习一直处于研究的前沿 计算机视觉 以及过去十年的深度学习.
在监督学习环境中,需要人工对大量数据集进行标注. 然后, 模型使用这些数据来学习数据和标签之间复杂的潜在关系,并开发预测标签的能力, 根据数据. 深度学习模型通常需要大量数据,需要大量数据集才能实现良好的性能. 不断改进的硬件和大型人工标记数据集的可用性是深度学习最近取得成功的原因.
监督式深度学习的一个主要缺点是,它依赖于大量人工标记的数据集进行训练. 这种奢侈并不是在所有领域都可用,因为获得专业人员注释的大型数据集可能在逻辑上很困难,而且非常昂贵. 虽然获取标记数据可能是一项具有挑战性且成本高昂的工作, 我们通常可以访问大量未标记的数据集, 尤其是图像和文本数据. 因此,我们需要找到一种方法来挖掘这些未被充分利用的数据集,并将它们用于学习.
在没有大量标记数据的情况下,我们通常使用 转移学习. 什么是迁移学习?
迁移学习是指使用从类似任务中获得的知识来解决手头的问题. 在实践中, 这通常意味着使用从类似任务中学习到的深度神经网络权重作为初始化, 而不是从随机初始化权重开始, 然后在可用的标记数据上进一步训练模型来解决手头的任务.
迁移学习使我们能够在小到几千个例子的数据集上训练模型, 它可以提供非常好的性能. 预训练模型的迁移学习可以通过三种方式进行:
通常, 神经网络的最后一层进行最抽象和特定任务的计算, 哪些通常不容易转移到其他任务. 相比之下, 网络的初始层学习一些基本特征,如边缘和常见形状, 哪些是容易在任务间转移的.
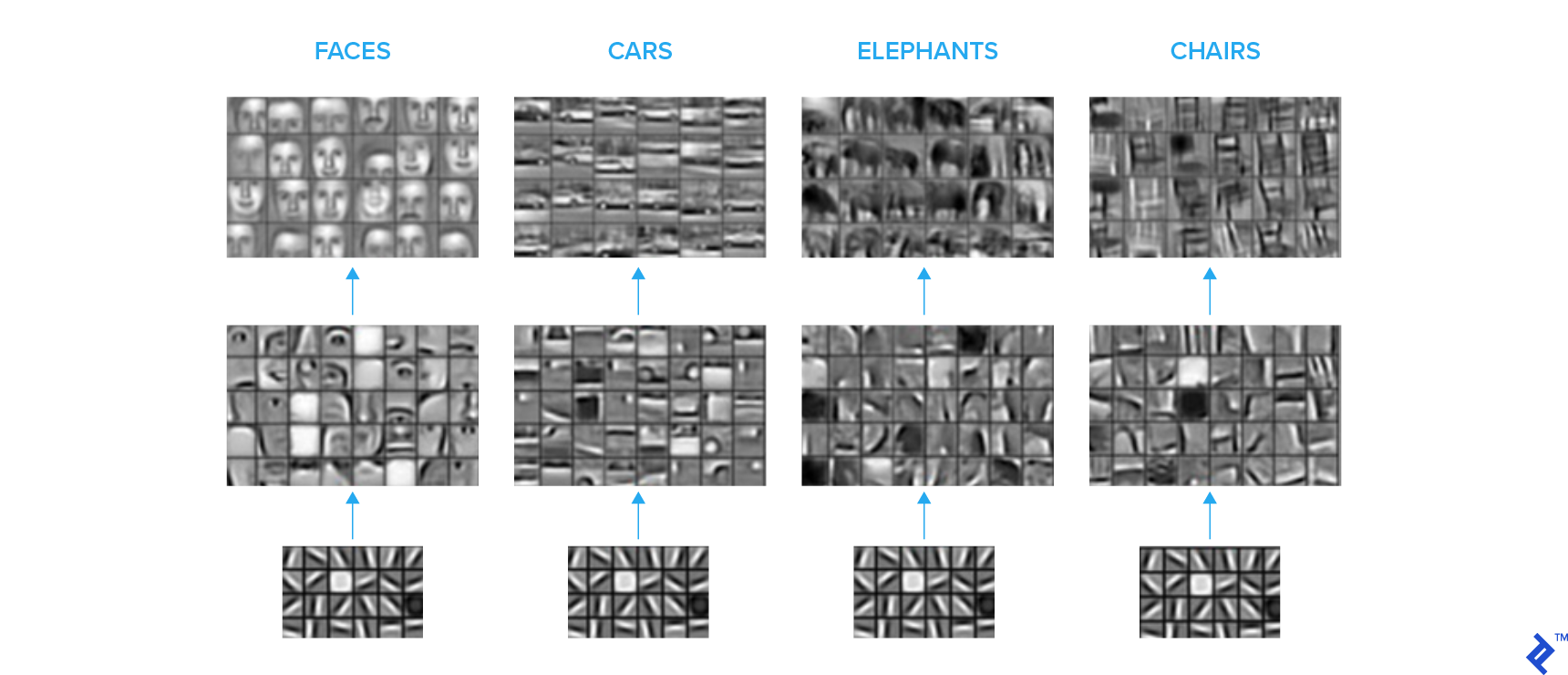
下面的图像集描述了卷积神经网络(CNN)中不同层次的卷积核本质上是在学习什么. 我们看到一个分层表示, 初始层学习基本形状, 并逐步, 更高层学习更复杂的语义概念.
一种常见的做法是在大型标记图像数据集(如 ImageNet),并在最后切掉完全连接的层. 新, 然后根据所需的类数量附加和配置完全连接的层. 转移的层被冻结, 新的层是在你的任务中可用的标记数据上训练的.
在这个设置中, 预训练模型被用作特征提取器, 顶部的完全连接层可以被认为是一个浅分类器. 这种设置比过拟合更健壮,因为可训练参数的数量相对较少, 因此,当可用的标记数据非常稀缺时,这种配置可以很好地工作. 多大的数据集才算非常小的数据集,这通常是一个需要多方面考虑的棘手问题, 包括手头的问题和模型主干的大小. 粗略地说,对于由几千张图像组成的数据集,我会使用这种策略.
另外, 我们可以从一个预训练的网络中转移这些层,并在可用的标记数据上训练整个网络. 这种设置需要更多的标记数据,因为你正在训练整个网络,因此有大量的参数. 当数据稀缺时,这种设置更容易出现过拟合.
这种方法是我个人最喜欢的,通常会产生最好的结果,至少在我的经验中是这样. 在这里, 在对整个网络进行微调之前,我们先训练新连接的层,同时将传输的层冻结几个epoch.
对整个网络进行微调而不给最终层几个epoch可能会导致有害梯度从随机初始化的层传播到基本网络. 此外, 微调需要相对较小的学习率, 两阶段方法是一个方便的解决方案.
对于大多数图像分类任务来说,这通常工作得很好,因为我们有像ImageNet这样的巨大图像数据集,覆盖了可能的图像空间的很大一部分, 从中学习的权重可以转移到自定义图像分类任务中. 此外,预训练的网络是现成的,从而促进了这一过程.
然而, 如果任务中的图像分布与训练基础网络的图像有很大不同,那么这种方法就不能很好地工作. 例如, 如果您正在处理由医疗成像设备生成的灰度图像, 从ImageNet的权值进行迁移学习不会那么有效,你需要超过几千张带标签的图像来训练你的网络以达到令人满意的性能.
相反,针对您的问题,您可以访问大量未标记的数据集. 这就是为什么从未标记的数据集中学习的能力是至关重要的. 另外, 未标记的数据集通常比最大的标记数据集在种类和数量上都要大得多.
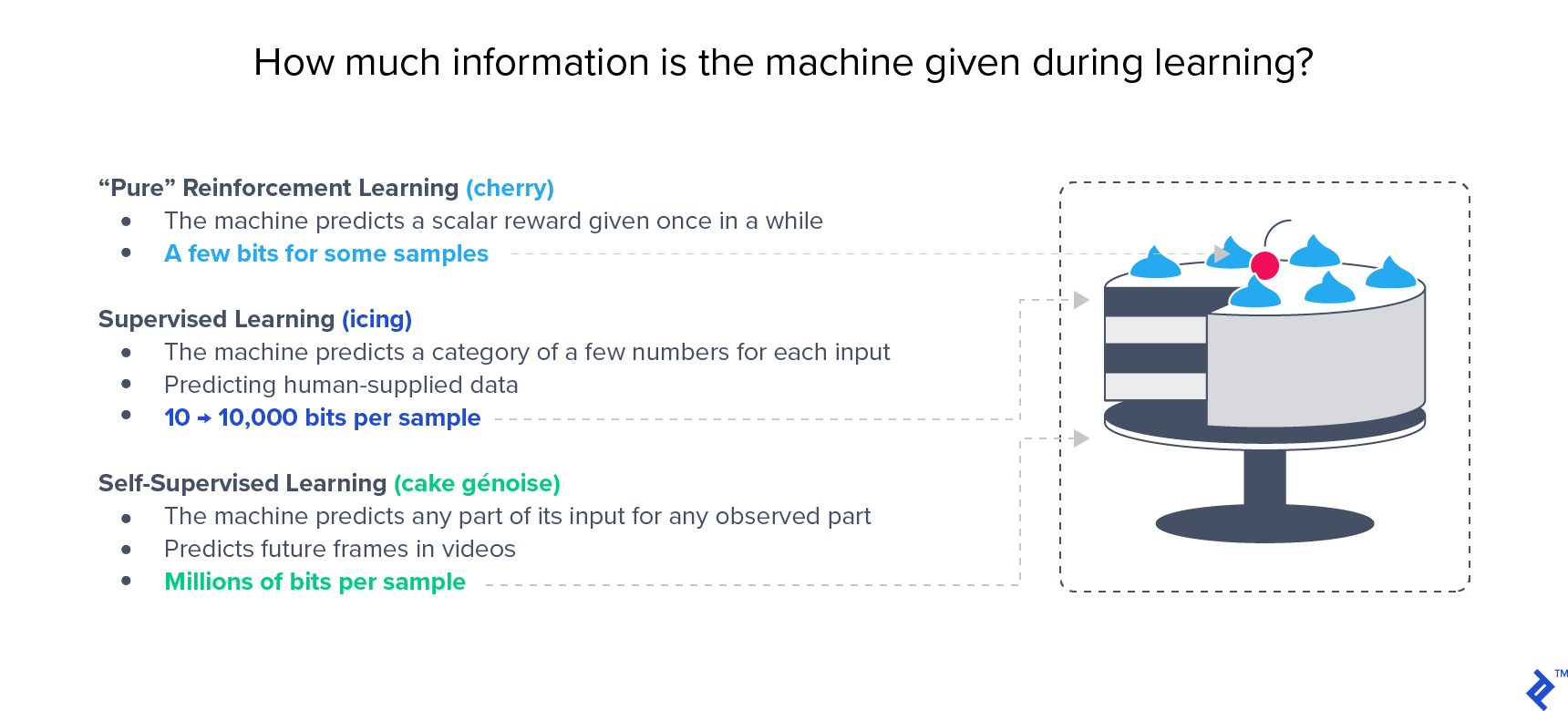
在像ImageNet这样的大型基准测试中,半监督方法已经显示出优于监督方法的性能. Yann LeCun很有名 蛋糕的类比 强调无监督学习的重要性:
这种方法利用标记和未标记的数据进行学习, 因此它被称为半监督学习. 当您有少量标记数据和大量未标记数据时,这通常是首选的方法. 有些技术可以让你同时从标记和未标记的数据中学习, 但我们将在两阶段方法的背景下讨论这个问题:对未标记数据的无监督学习, 迁移学习使用上面描述的策略之一来解决你的分类任务.
在这些情况下,无监督学习是一个相当令人困惑的术语. 这些方法并不是真正的无监督的,因为有一个监督信号来指导权重的学习, 而监控信号则来源于数据本身. 因此, 它有时被称为自我监督学习,但这些术语在文献中可以互换使用,指的是相同的方法.
自监督学习的主要技术可以根据它们如何从数据中生成监督信号来划分, 如下所述.
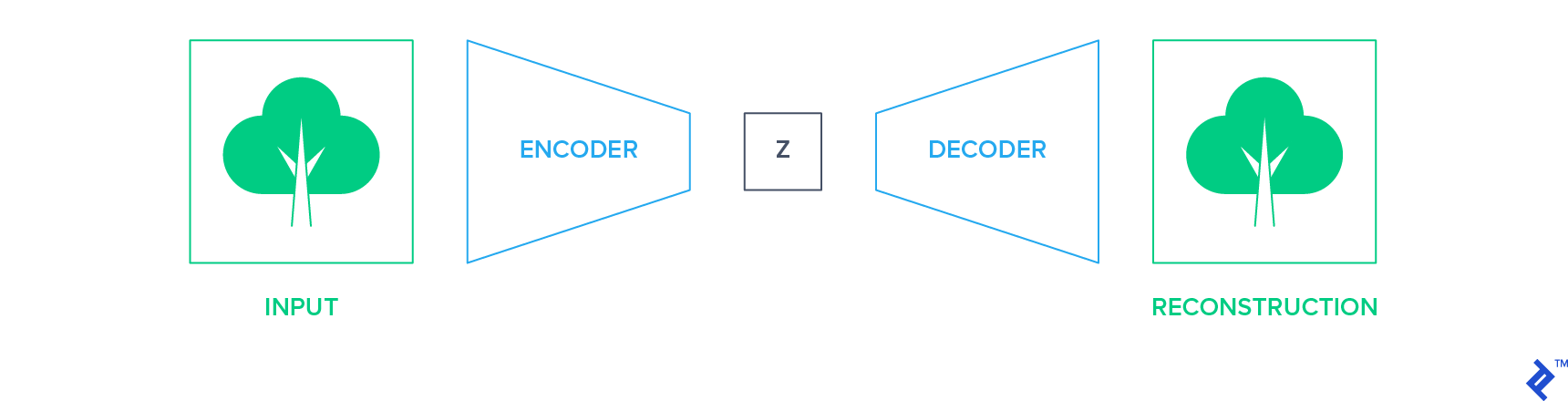
生成方法的目的是在数据通过瓶颈后精确地重建数据. 这种网络的一个例子是自动编码器. 他们使用编码器网络将输入减少到低维表示空间,并使用解码器网络重建图像.
在这种设置中,输入本身成为训练网络的监督信号(标签). 然后可以提取编码器网络并将其用作构建分类器的起点, 使用上述部分讨论的迁移学习技术之一.
同样,另一种形式的生成网络 生成对抗网络 (gan) -可用于未标记数据的预训练. 然后,可以采用鉴别器并对分类任务进行进一步微调.
判别方法训练神经网络学习辅助分类任务. 选择一个辅助任务,使监督信号可以从数据本身派生出来, 无需人工注释.
这类任务的例子是学习图像补丁的相对位置, 对灰度图像进行着色, 或者学习应用在图像上的几何变换. 我们将进一步详细讨论其中的两个.
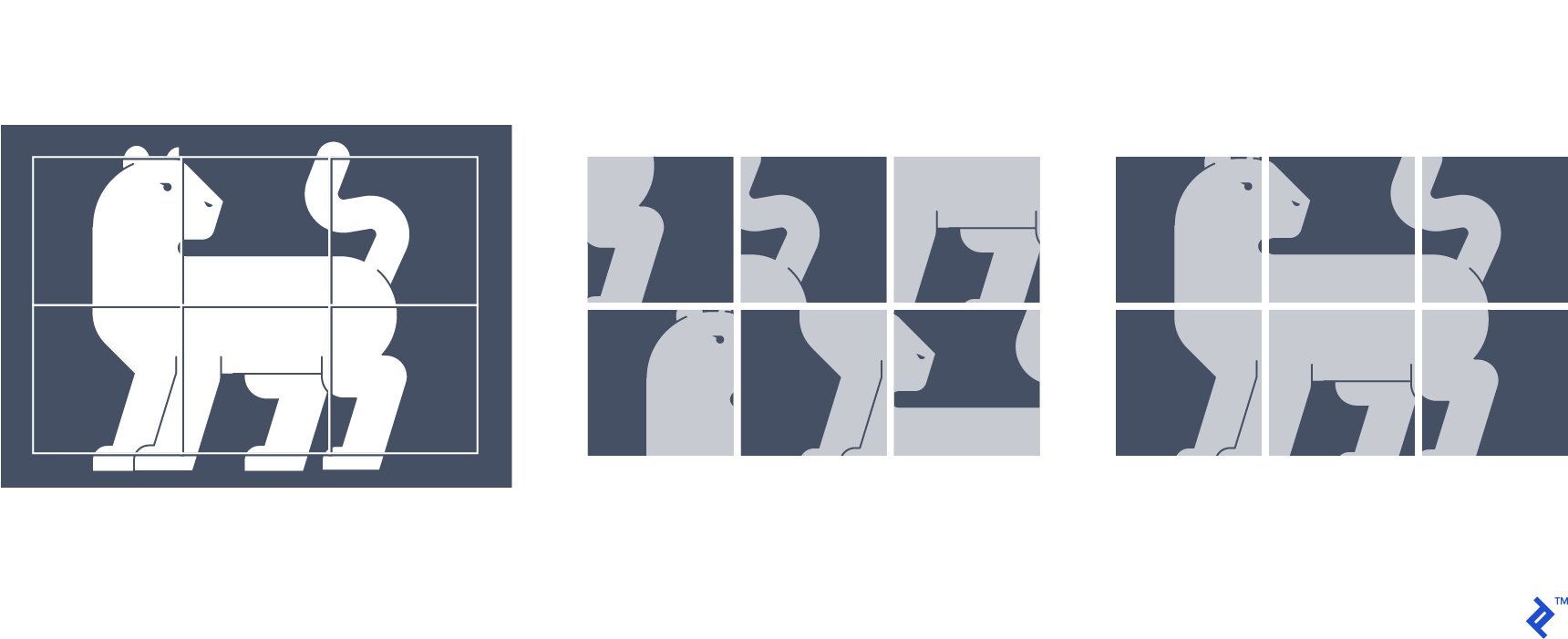
在这个技术中, 从源图像中提取图像补丁,形成类似拼图的网格. 路径位置被洗牌, 洗牌后的输入被输入到网络中, 哪一个经过训练可以正确地预测网格中每个补丁的位置. 因此,监督信号就是每条路径在网格中的实际位置.
在学习中, 该网络学习物体的相对结构和方向,以及颜色等低级视觉特征的连续性. 结果表明,通过解决这个拼图学到的特征可以高度转移到图像分类和目标检测等任务中.
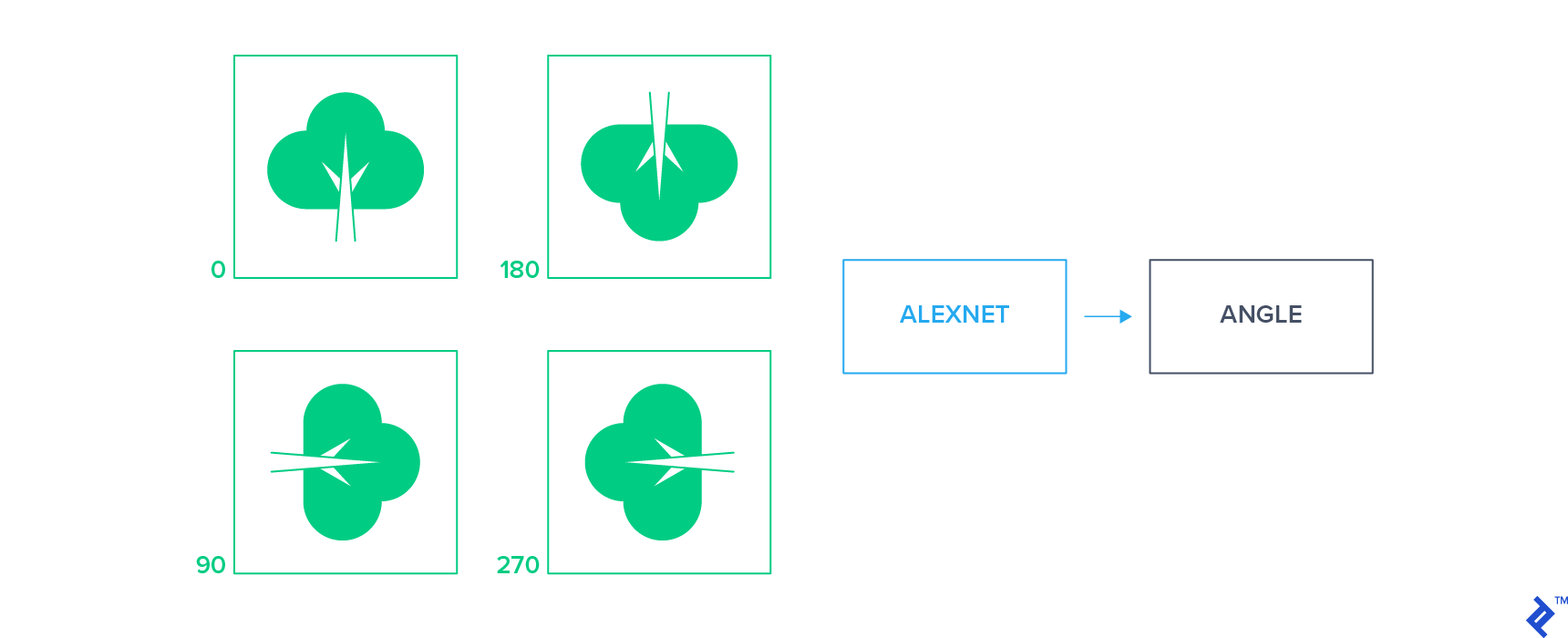
这些方法对输入图像应用一小组几何变换,并训练分类器通过单独查看变换后的图像来预测应用的变换. 这些方法的一个例子是对未标记的图像应用2D旋转以获得一组旋转的图像,然后训练网络来预测每个图像的旋转.
这个简单的监督信号迫使网络学会定位图像中的物体并理解它们的方向. 通过这些方法学习的特征已被证明是高度可转移的,并且在半监督设置中为分类任务提供了最先进的性能.
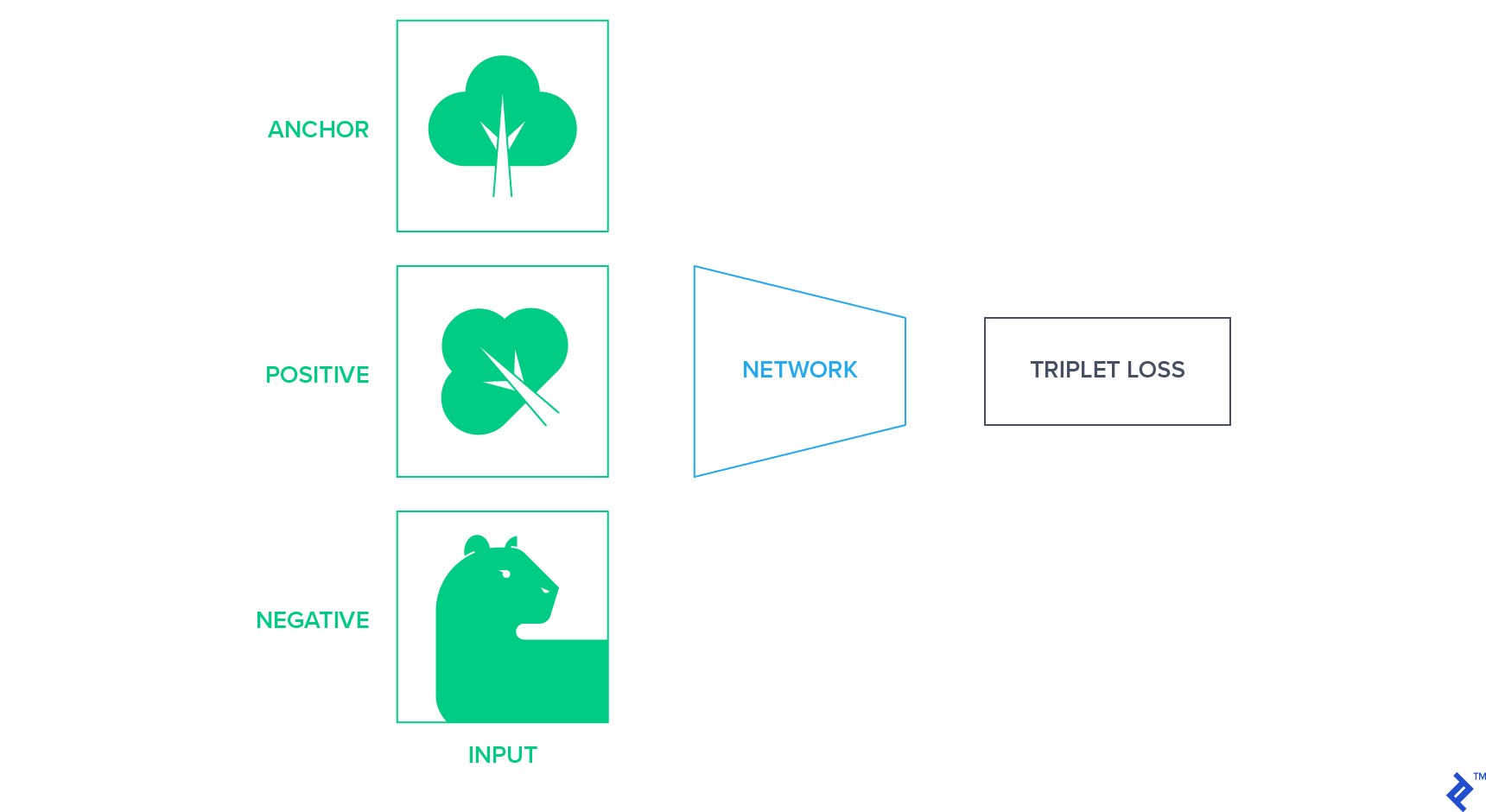
这些方法将图像投影到一个固定大小的表示空间中,在这个空间中,相似的图像靠得更近,而不同的图像离得更远. 实现这一点的一种方法是使用 暹罗网络 基于三联体损失,最小化语义相似图像之间的距离. 三重损失需要一个锚, 一个积极的例子, 和一个消极的例子,并试图使积极的更接近锚,而不是消极的,就潜在空间的欧几里得距离而言. Anchor和positive是同班同学, 负例是从剩下的类中随机选择的.
在未标记数据中, 我们需要想出一种策略,在不知道图像类别的情况下,产生锚定的正面和负面例子的三联体. 一种方法是使用锚图像的随机仿射变换作为正例,并随机选择另一个图像作为负例.
在本节中, 我将涉及一个实验,从经验上建立了图像分类的无监督预训练的潜力. 这是我的学期课题 深度学习课程 我去年春天在纽约大学和Yann LeCun一起做的.
我们训练了7个模型,每个模型在每个类中使用不同数量的标记训练样本. 这样做是为了了解训练数据的大小如何影响我们的半监督设置的性能.
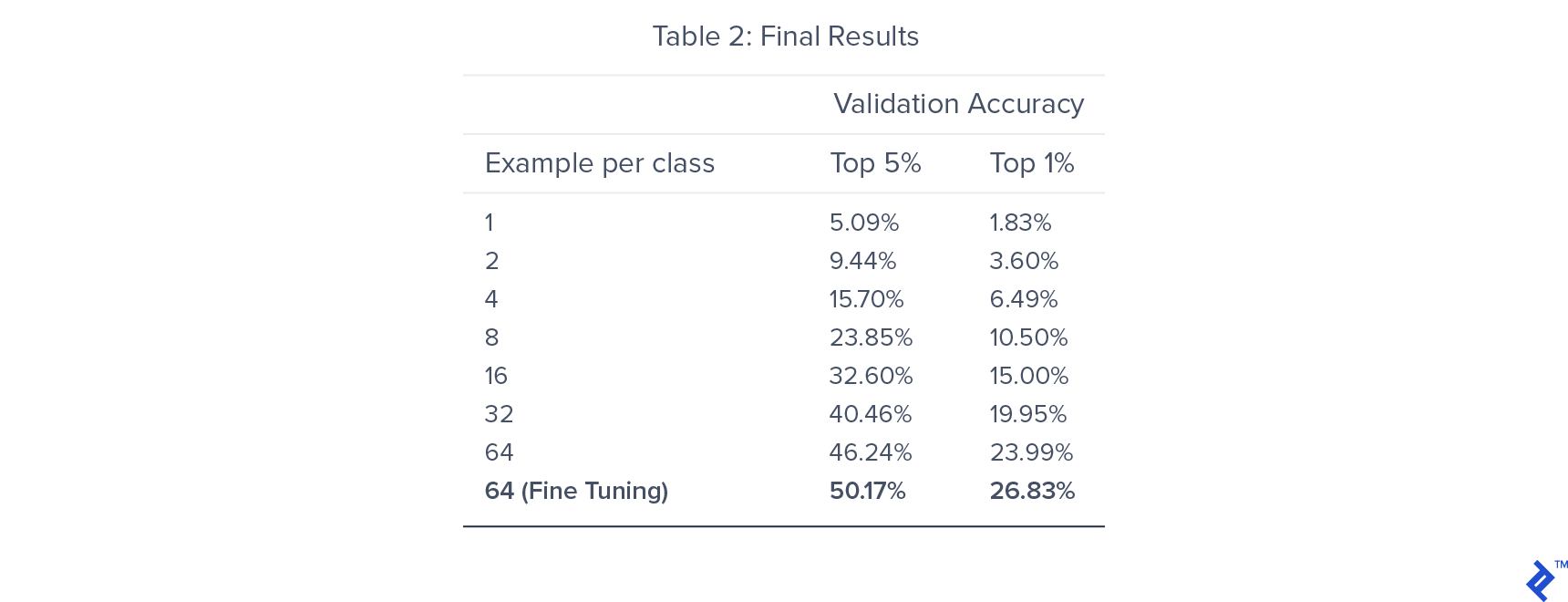
我们能够在旋转分类的预训练中获得82%的准确率. 对于分类器训练,前5%的准确率在46附近饱和.24%,对整个网络进行微调,最终得出的数字是50.17%. 通过利用预训练, 我们得到了比监督训练更好的效果, 哪个给出了前5名40%的准确率.
正如预期的那样,验证精度随着标记训练数据的减少而降低. 然而, 在有监督的环境下,性能的下降并不像人们所期望的那样显著. 训练数据从每个类64个示例减少到每个类32个示例,减少50%只会导致验证准确性降低15%.
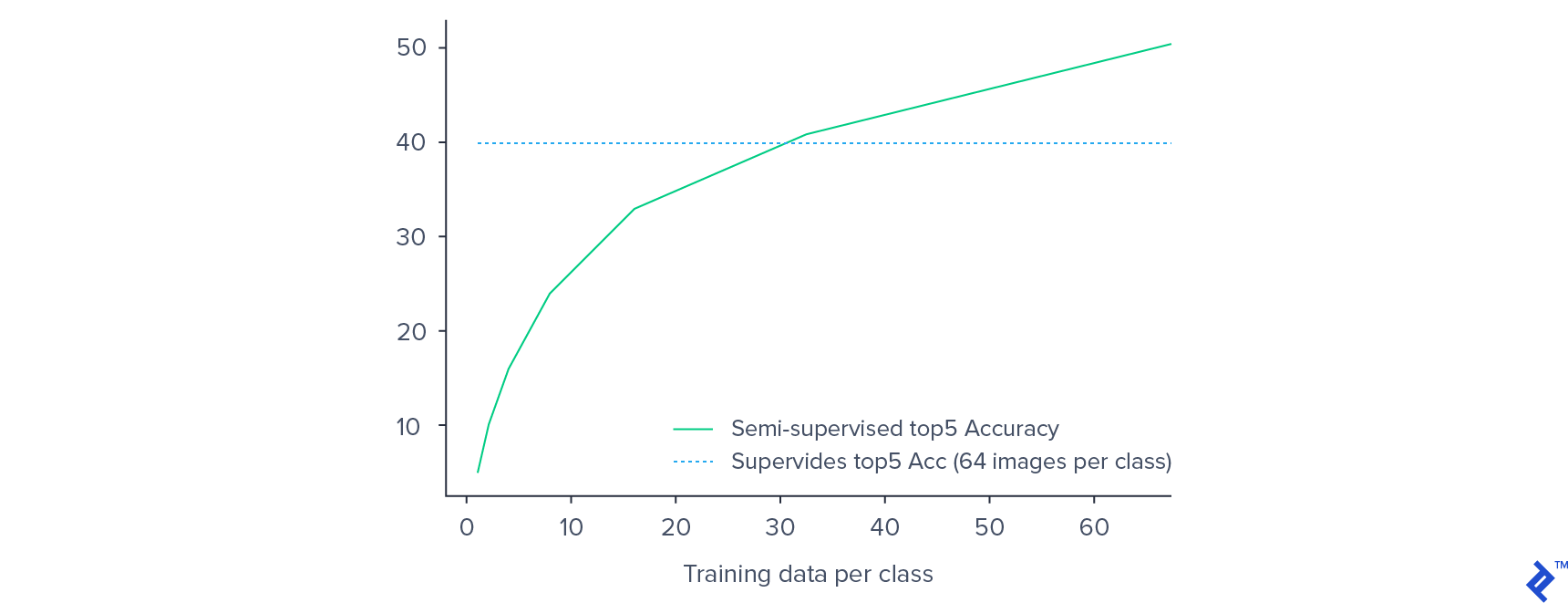
每个类只使用32个示例, 我们的半监督模型比每个类使用64个样本训练的监督模型具有更好的性能. 这为半监督方法在低资源标记数据集上的图像分类潜力提供了经验证据.
我们可以得出结论,无监督学习是一个强大的范例,有能力提高低资源数据集的性能. 无监督学习目前处于起步阶段,但通过从廉价且易于获取的未标记数据中学习,将逐渐扩大其在计算机视觉领域的份额.
在有监督的学习环境中, 模型同时提供数据和标签, 哪个通常是手动注释的. 然后,模型学习将数据映射到标签的函数,从而开发预测标签的能力, 根据数据.
有监督机器学习的两大类是分类和回归. 回归试图将输入数据映射为连续变量, 而分类则将输入映射到一个离散变量.
在监督学习中, 我们已经标记了对学习至关重要的数据, 在无监督学习中, 我们不需要提供标签.
深度学习本质上是机器学习的一个子集, 所以监督学习的定义是一样的.
监督图像分类将图像映射到为它们提供的标签. 无监督图像分类是基于图像之间的内在相似性和差异性将图像分成不同的组, 没有任何标记数据.
世界级的文章,每周发一次.
世界级的文章,每周发一次.



 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.